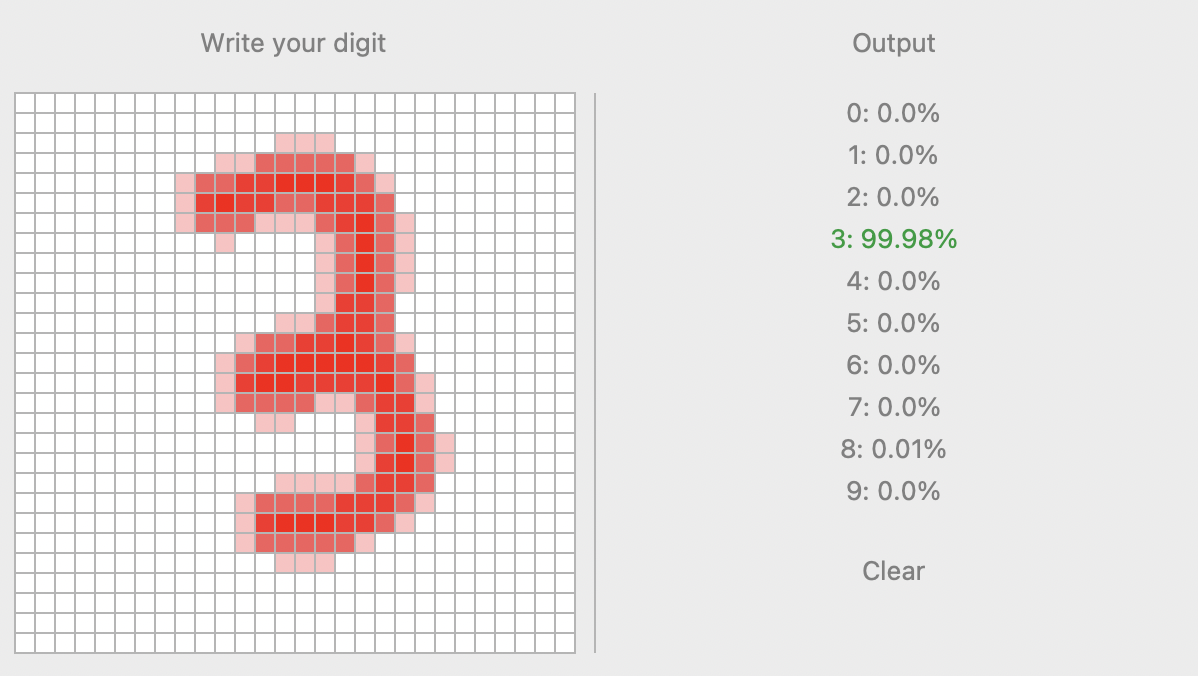
The goal is to create a software able to recognise handwritten digits drawn by the user using a graphical interface.
The project consists in two separate parts: first, finding and optimising the predictive model, and second, creating the program that receives the input from the user and uses that model to interpret it.
In oder to train and test the model, I have used the MNIST handwritten digits dataset, that contains thousands of 28x28 examples in grey scale: the value of the pixel ranges from 0 (white) to 1 (black).
I have used a Jupyter Notebook to prepare the dataset by splitting it between the train and test sets and standardising them. Then, I focused on the models. Two models, in particular, reached a noticeable test accuracy: the Support Vector Classifier (97%) and the neural network (97.5%). Being both promising, I saved them in order to test them on the user input.
Optimising the SVC has required, in order to be trained in a reasonable time, a drastic dimensionality reduction, for which I have used the principal component analysis.
As like with other projects, the graphical interface relies on tkinter. On the left, I have built a 28x28 grid of white cells where the user will write the digits. On the right, instead, there are the ten possible outputs of the models and their respective probability.
The grid on the left is the area where the user can click and drag the mouse to colour the cells. Once the mouse button is released, the entire grid is saved in an array that, as like the digits in the dataset, contain 0 for the white cells and 1 for the coloured ones.
The digits obtained as written above, unfortunately, were quite different from the ones contained in the dataset: first of all, the former were thinner, and secondly, their array only contained zeros and ones, without any shade. This, together with the fact that the models seemed completely useless, made me look for a way to make the new digits more similar to the ones with which the algorithm was trained.
After several attempts, I have chosen this solution: when a cell is clicked, it now gets coloured together with the four adjacents cells, and, when the mouse button is released, all the cells take as value the mean between the 8 neighbouring cells. The result and the performance of the models immediately and noticeably improved.
The filter:

The project was, overall, successful. The software, though far from perfect, is able to recognise the digits fairly well. Moreover, the neural network works way better than the SVC. However, it is at the same time weird and interesting that its performance improves considerably if the software does not standardise the new input like it was done with the train and test set. In my opinion, this happens because the standardisation is strictly related to the datapoints, and therefore to the original generative process, filtering and encoding of the digits used to build the dataset. My home-made filter, probably, creates results that are still quite different. A noticeable limit of the model is that the ability of recognising the same digit varies according to its position on the grid: the ones at the center are more easily recognised than the ones a bit shifted.
Some examples: