Il progetto consiste nel creare un programma in Python che riconosca cifre scritte a mano dall'utente attraverso un'apposita interfaccia grafica.
Il progetto consiste in due parti distinte: la ricerca del modello predittivo e la creazione del programma che riceve l'input dell'utente e sfrutta quel modello per riconoscere le cifre.
Per allenare e testare il modello ho usato il dataset di cifre scritte a mano MNIST. Questo dataset contiene immagini 28x28 in scala di grigi: esse sono rappresentate da una array di uguali dimensioni dove il valore di un pixel va da 0 (bianco) a 1 (nero).
Usando un Jupyter Notebook l'ho preparato dividendolo nelle parti di train e test e standardizzandolo, poi mi sono concentrato sul modello. Ho trovato e cercato di ottimizzare due modelli che hanno raggiunto prestazioni molto buone: un Support Vector Classifier (scikit-learn) e una rete neurale (PyTorch). In particolare, l'SVC ha raggiunto una accuracy di test del 97% e la rete neurale del 97.5%. Essendo entrambi promettenti, ho deciso di salvarli entrambi per testarli sull'input dell'utente.
Ottimizzare l'SVC ha inoltre richiesto, per poter essere impiegato in tempi ragionevoli, una drastica riduzione di dimensionalità, per farlo ho usato l'analisi delle componenti principali.
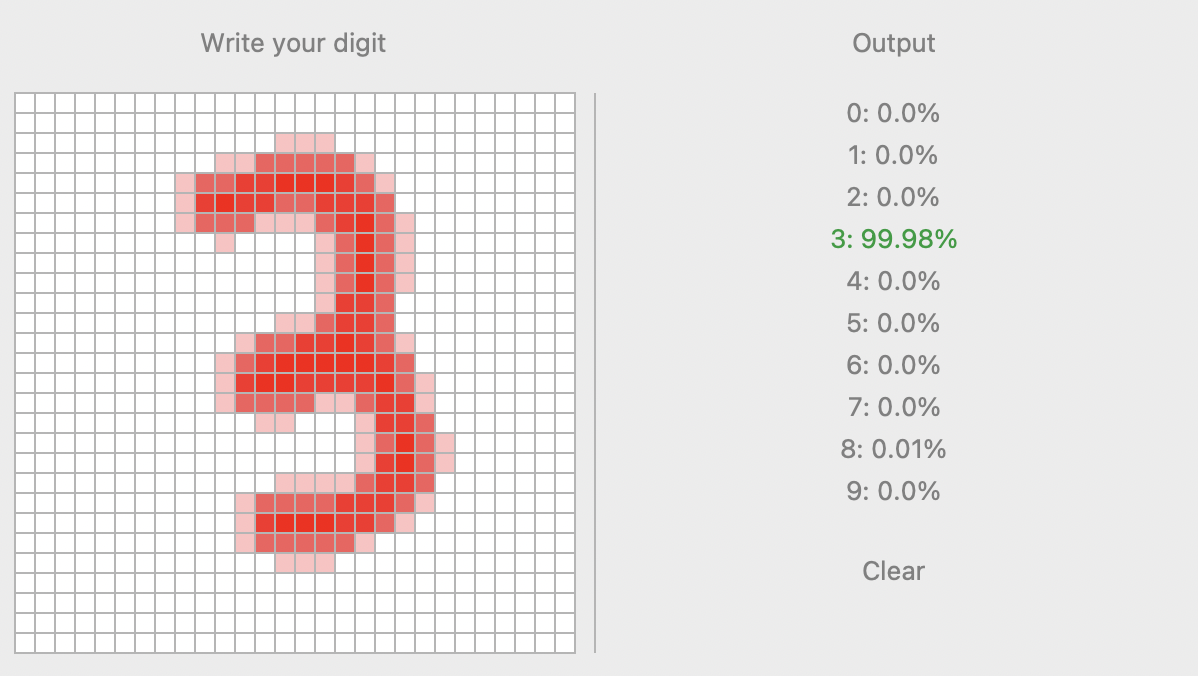
Come per altri progetti, ho usato tkinter per gestire l'interfaccia grafica. Sulla sinistra ho crato una griglia 28x28 di riquadri bianchi dove l'utente disegnerà le cifre, mentre a destra sono presenti le 10 possibili previsioni del modello, le loro rispettive probabilità e un pulsante per svuotare il contenuto.
La griglia sulla sinistra funge da area di scrittura, dove l'utente passa il mouse e cliccando colora le caselle. Una volta che l'utente ha terminato la cifra, e il pulsante del mouse viene rilasciato, l'intera griglia viene memorizzata in una array che, come le cifre del dataset, contiene 0 per le caselle bianche e tra 0 e 1 per quelle colorate.
Le cifre ottenute nel modo indicato sopra, purtroppo, erano molto diverse da quelle contenute nel dataset: in primo luogo lo spessore del tratto era costante e molto più sottile, in secondo luogo i pixel erano o 0 o 1, senza nessuna sfumatura. Questo, insieme al fatto che i modelli trovati precedentemente non azzeccavano una previsione, mi ha fatto cercare un modo rendere le cifre disegnate più simili possibili a quelle su cui l'algoritmo si è allenato.
Dopo diversi tentativi ho scelto questa soluzione: ho ingrandito il tratto di colore generato dal mouse, ora, quando il mouse cliccato passa su una cella, viene colorata lei ma anche le quattro celle adiacenti, poi ho fatto in modo che, terminato il disegno, ogni cella assumesse il valore medio tra lei e le 8 celle vicine. Il risultato e la performance dei modelli sono migliorati notevolmente:

Il progetto è complessivamente riuscito: il programma, pur non essendo perfetto, riconosce abbastanza spesso la cifra giusta. La rete neurale funziona molto meglio dell'SVC, e, cosa strana ma interessante, solo non applicando la standardizzazione applicata al dataset originale al nuovo input. Per spiegarmi questa cosa ho ipotizzato che la struttura dei dati e di conseguenza questa standardizzazione dipendesse strettamente dall'encoding e dal filtro usato per creare il dataset, e quindi il mio ritocco fatto a mano al disegno dell'utente non fosse abbastanza simile. Un limite che si può notare facilmente è la differenza di interpretazione causata dalla posizione della cifra nella griglia: se posizionata al centro è più facilmente riconosciuta che in altri punti.
Qualche esempio: