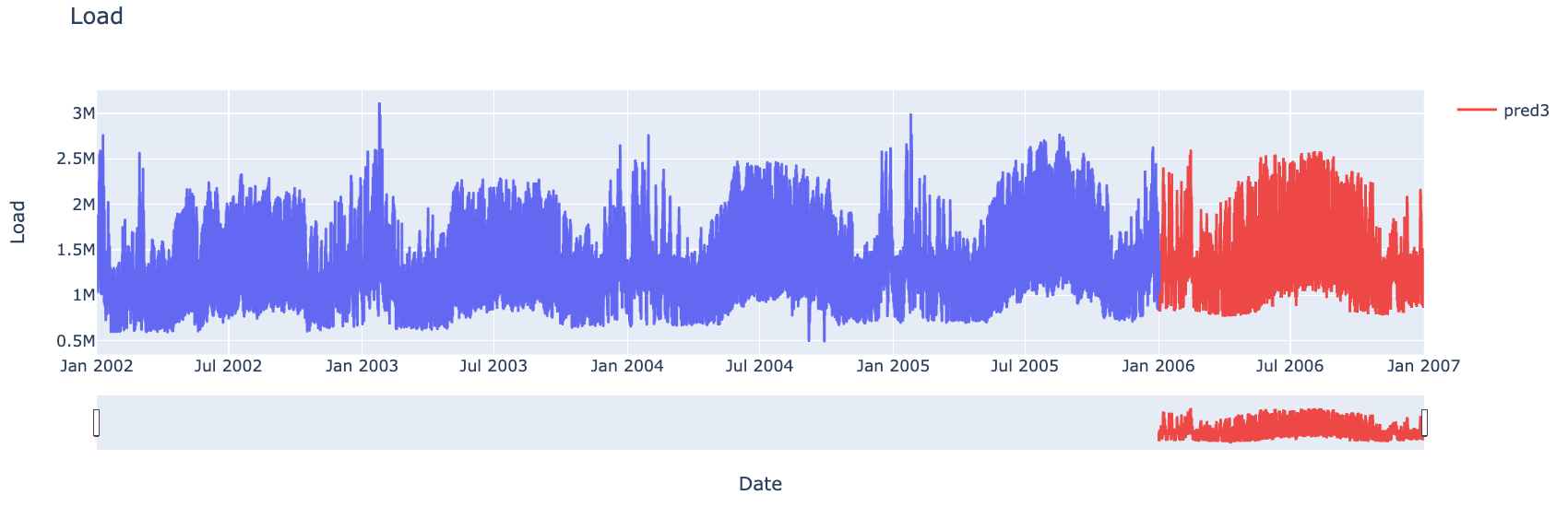
Quando ho frequentato il corso di Business Forecasting alla University of Southern California, ho partecipato a una Data Science competition di classe a squadre, con l'obiettivo di prevedere un anno di consumo di energia elettrica orario di una cittá per una ipotetica azienda fornitrice. Più precisamente, il dataset conteneva una serie storica di quattro anni, dal 2002 al 2005, di dati di consumo orario insieme a quattro misure della temperatura (media, mediana, minima, massima) registrate durante quell'ora.
Oltre a prevedere il consumo orario per il 2006, ogni squadra doveva fornire una previsione del picco di carico giornaliero, e dell'orario a cui sarebbe avvenuto questo picco.
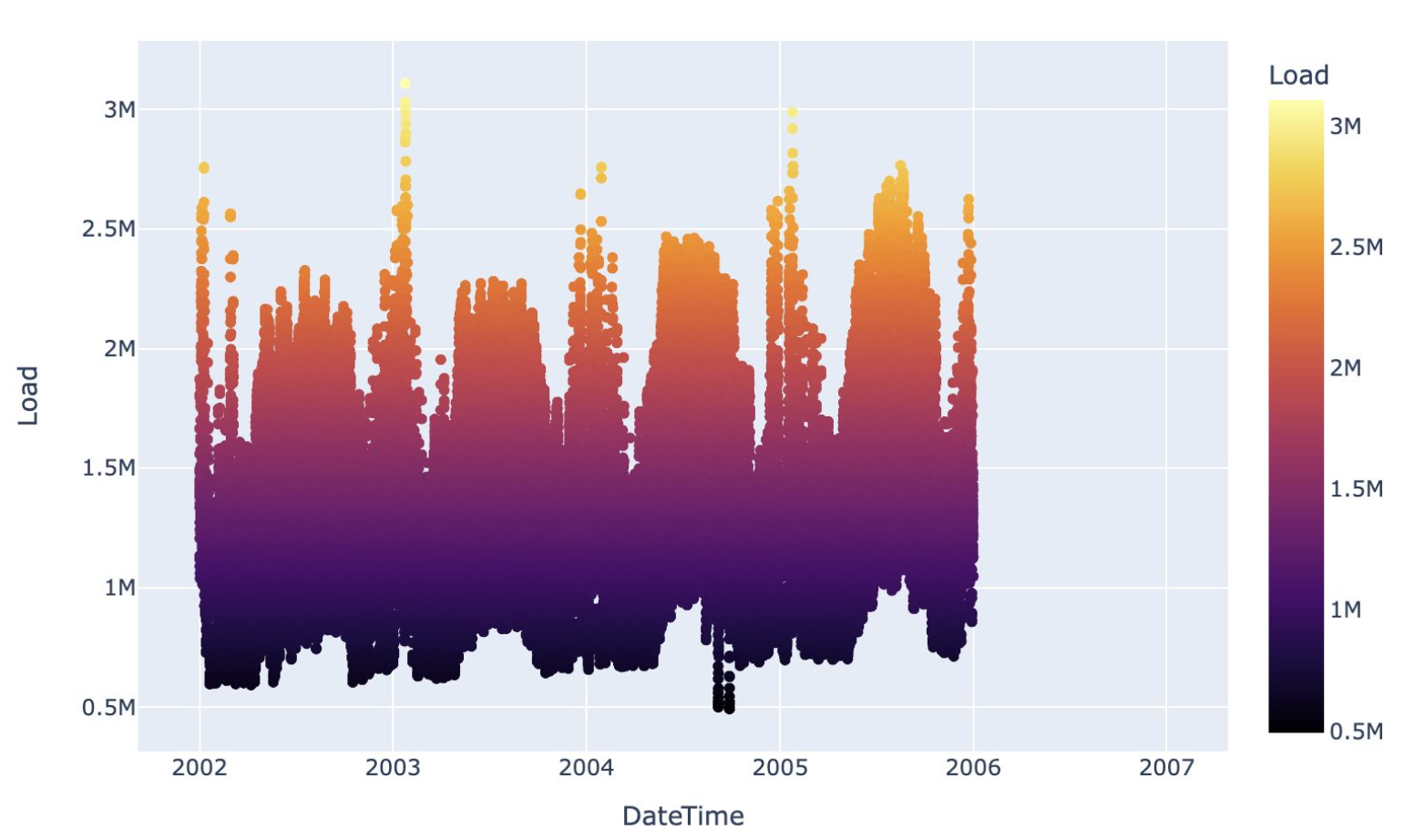
Per iniziare, io e la mia squadra abbiamo svolto analisi esplorative del dataset. In particolare, abbiamo voluto indagare i diversi livelli di stagionalitá presenti nella serie storica. Essendo dati orari, abbiamo ipotizzato che il consumo di elettricitá potesse variare su diversi livelli:
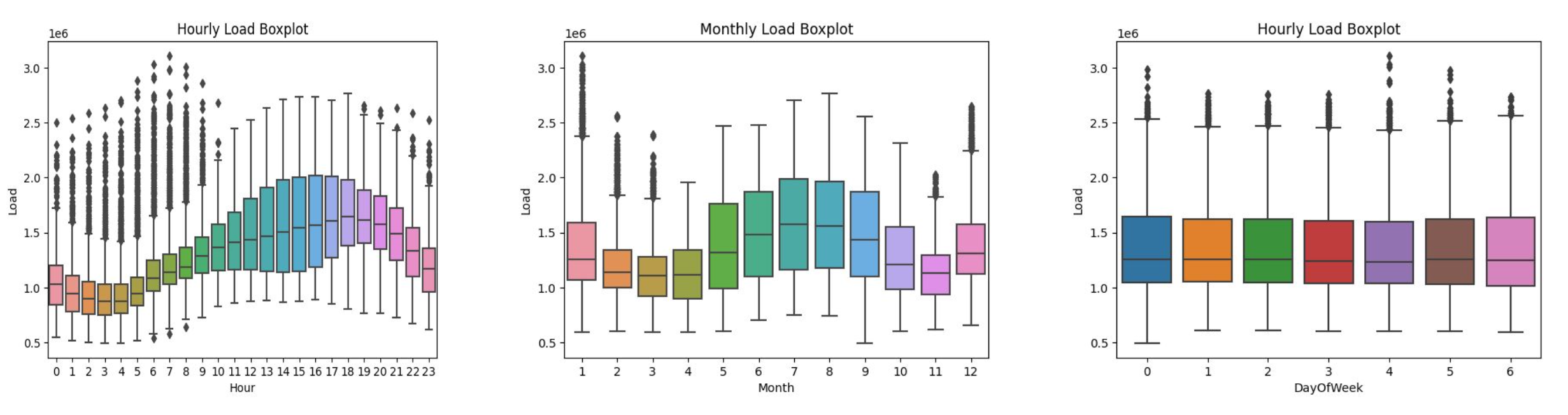
Studiare a fondo questi livelli di stagionalitá é stato essenziale per poi capire come modellare al meglio la serie storica. Abbiamo verificato, per esempio, che la stagionalitá settimanale é poco significativa, e che la relazione tra domanda di elettricitá e temperatura fosse inversa tra i mesi invernali, dove la domanda dovuta al riscaldamento aumenta con temperature più basse, e estivi, per cui la domanda aumenta per temperature più alte.
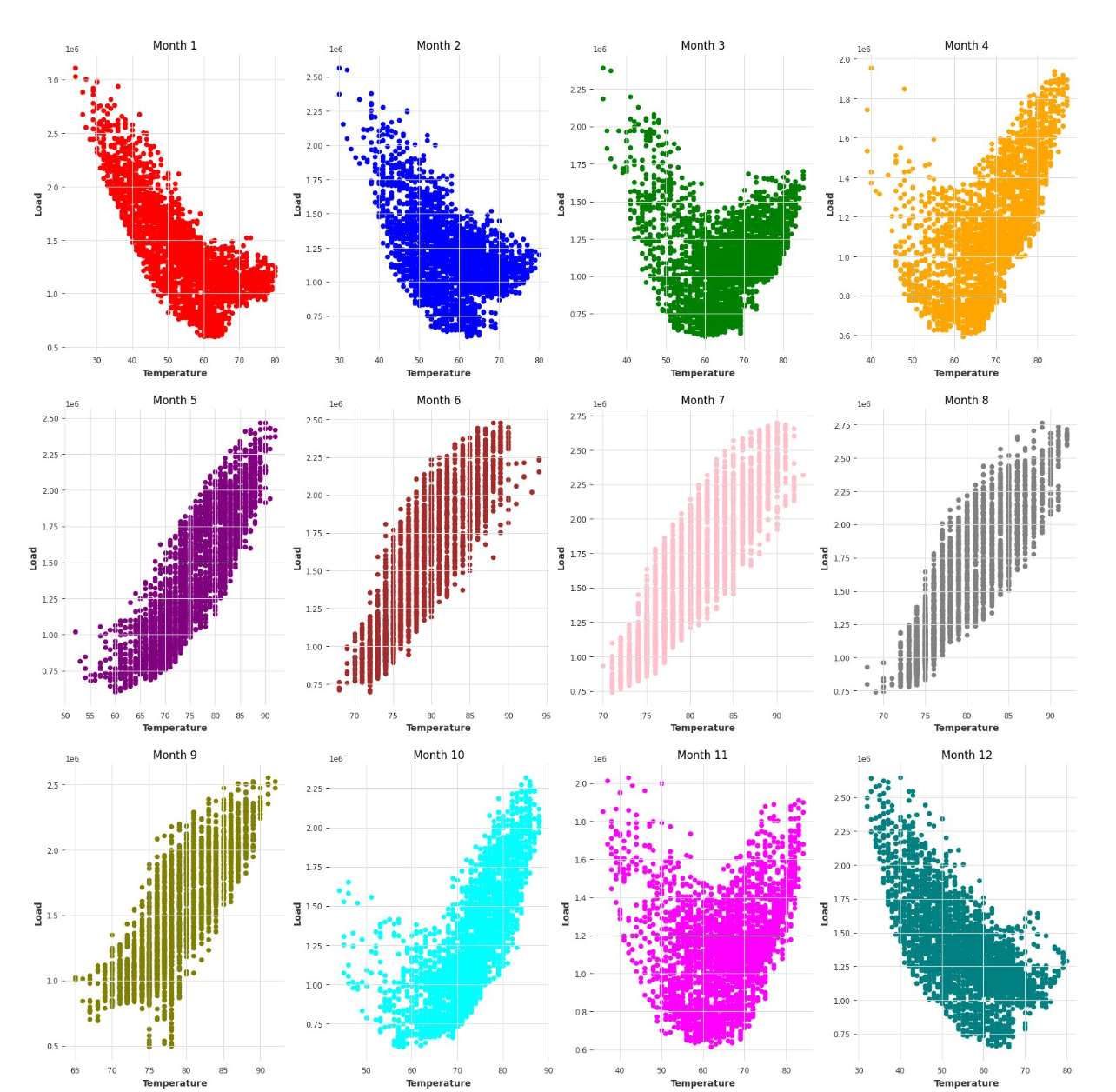
Dopo aver esplorato la serie storica, la seconda fase del progetto é stata la generazione di feature che potessero essere utili per i modelli predittivi che avremmo usato. Per prima cosa io e la mia squadra abbiamo generato dummy variables per modellare i diversi livelli di stagionalitá, quindi dummy per l'ora del giorno, il giorno, il mese, l'anno, il trimestre, il giorno della settimana e così via. Inoltre, abbiamo alcuni lag dei valori di consumo e di temperatura passati, e una variabile per misurare il trend.

Abbiamo diviso il dataset in una parte di train, gli anni 2002-2004, e una parte di test, 2005, così da ottenere una stima di come sarebbero state le performance dei modelli che saremmo andati ad allenare su dati nuovi. Successivamente, abbiamo allenato e ottimizzato diversi tipi di modelli predittivi, per esempio:
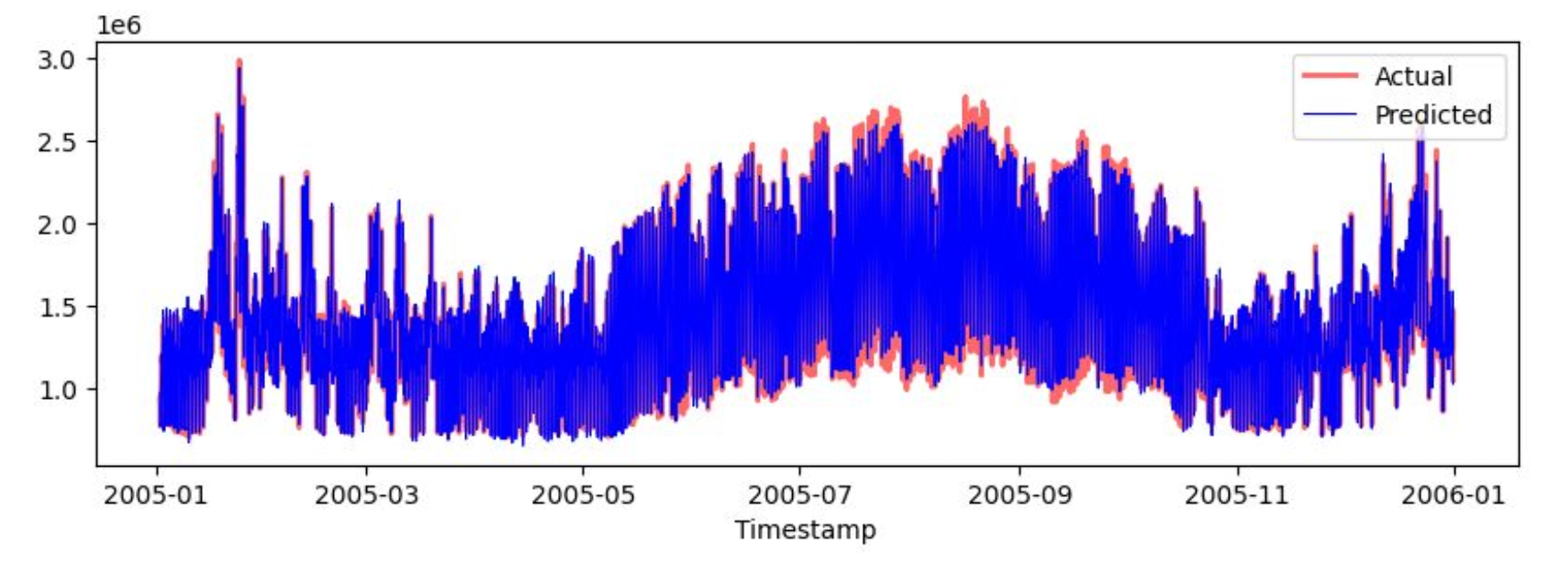
Dopo aver condotto alcune ricerche, abbiamo cercato di migliorare il modello Extreme Gradient Boosting (XGBoost) includendo alcune componenti delle Serie di Fourier per modellare meglio le stagionalitá della serie storica. Inoltre, abbiamo usato una 3-fold time-series cross-validation per migliorare le capacitá di generalizzazione del modello. In questo modo, la precisione delle previsioni é notevolmente aumentata, assestandosi a un MAPE del 4.96%.
A partire dal nostro modello migliore, abbiamo generato le nostre previsioni per l'anno 2006. Per quanto riguarda il picco di consumo giornaliero e l'ora del giorno in cui sarebbe avvenuto, nonostante fossimo riusciti a ottenere modelli ad hoc con performance accettabili, abbiamo deciso di costruire le nostre previsioni da quelle di consumo orario. Infatti, nonostante ci fosse il rischio di propagare gli errori di quel modello, io e il mio gruppo abbiamo pensato che, venendo queste previsioni utilizzate da una ipotetica azienda fornitrice di energia elettrica, ci sarebbe stato il rischio di fornire dati contraddittori. Utilizzando le stesse previsioni, invece, le indicazioni sarebbero state coerenti.